
A linguistic edge
a critical analysis + case study on phonetics

It is remarkable that of all the earthly species, only one developed a system for generating and sharing infinite meaning. Human language as we know it is a mono-species phenomena that underpins the entire arena of language-based possibility. Language as we know it is far from absolute. Sound, structure, meaning— there are possible forms that the actual has not claimed. We encounter glimpses of what else could be in the rare and fascinating genre of linguistic science fiction1.
To demonstrate the unfinished edges of linguistic possibility, I want to first turn to concrete examples in phonetics: the mechanics of speech. This lingustic domain seeks to map all possible sounds, even those unused in human language. This becomes the repertoire of linguistically meaningful sound.
The body as a wind instrument
Vocalization is all about how air is manipulated on its way in and out of the body. The architecture of the body generates each individual’s acoustic signature and distinguishes you from me, and us from birds.
During my linguistics studies, I became acutely aware of the way people spoke, imagining corresponding phonetic symbols as subtitles. For instance my Swedish friend’s whispery accent. To me, “raspberries” is /ˈɹæzˌbɛɹiz/ where the s’s had hard /z/ sounds, but for her it’s /ˈɹæsˌbɛɹis/ where the s’s had soft sound. The only difference between these sounds is that your vocal cords are either vibrating /z/ or not /s/. The Swedes are quite literally soft spoken people.
These phonetic symbols are characters from the International Phonetic Alphabet (IPA), a universal system for transcribing human speech. It depicts individual units of sounds (called phones) and is impressively comprehensive. It works for every language and is even possible to transcribe beat-boxing using IPA2. You can write the sound of a kiss as [ʘ], known as a bilabial click. It seeks to include all possible sounds, even those never observed in human language, leaving none unaccounted for— unless you have an anatomical adaptation.
Voices on the edge
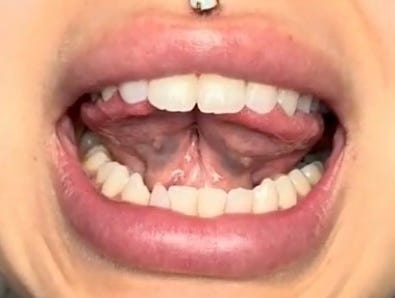
In college, I met someone with a bifurcated (split) tongue and immediately wondered how the novel sounds she could make with two tongues would fit into the current phonetic system. They don’t. This person was capable of creating sounds we had no definers for. What is compelling about this is how a small slit of flesh ruptures the phonetic alphabet’s canonical framework.
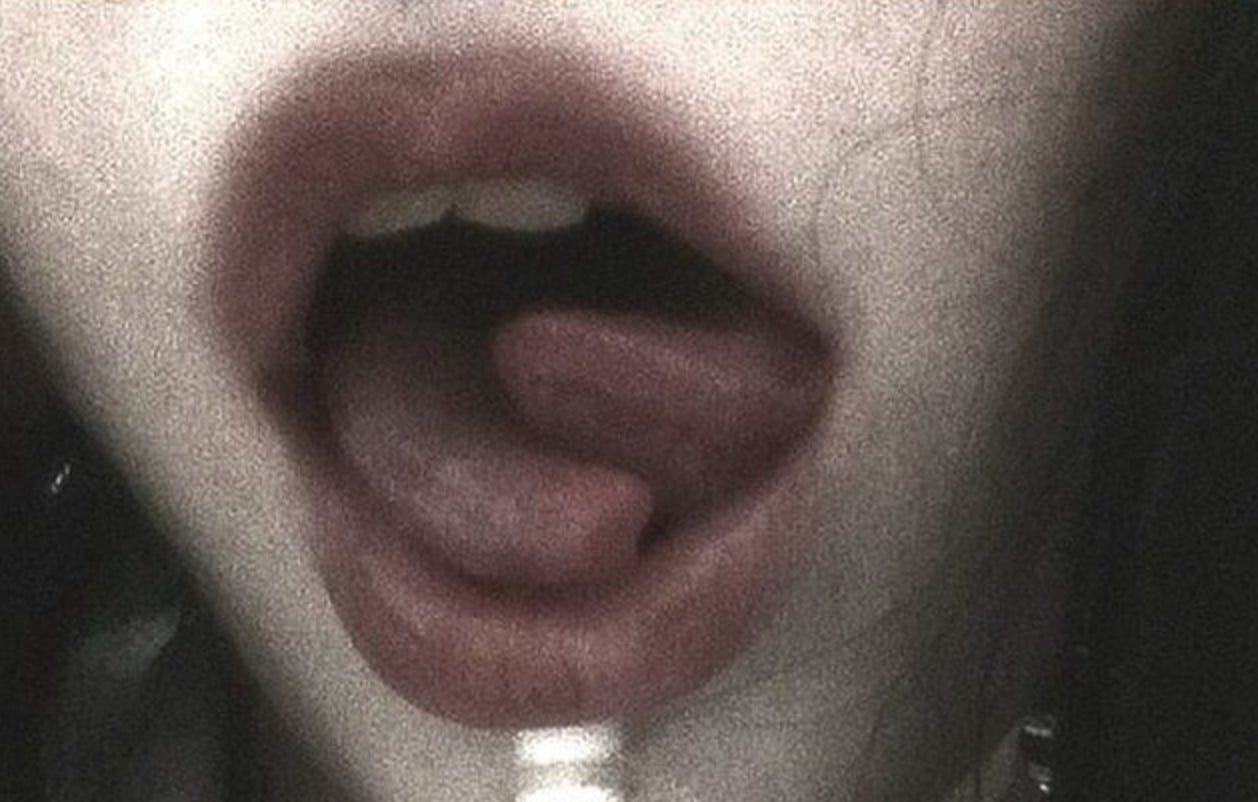
Another example of individuals who can meaningfully expand the phonetic potential of human speech are those who can achieve Khecarī mudrā, a yoga move where the tongue is pulled back and slips into the nasal cavity. This is how it’s done:
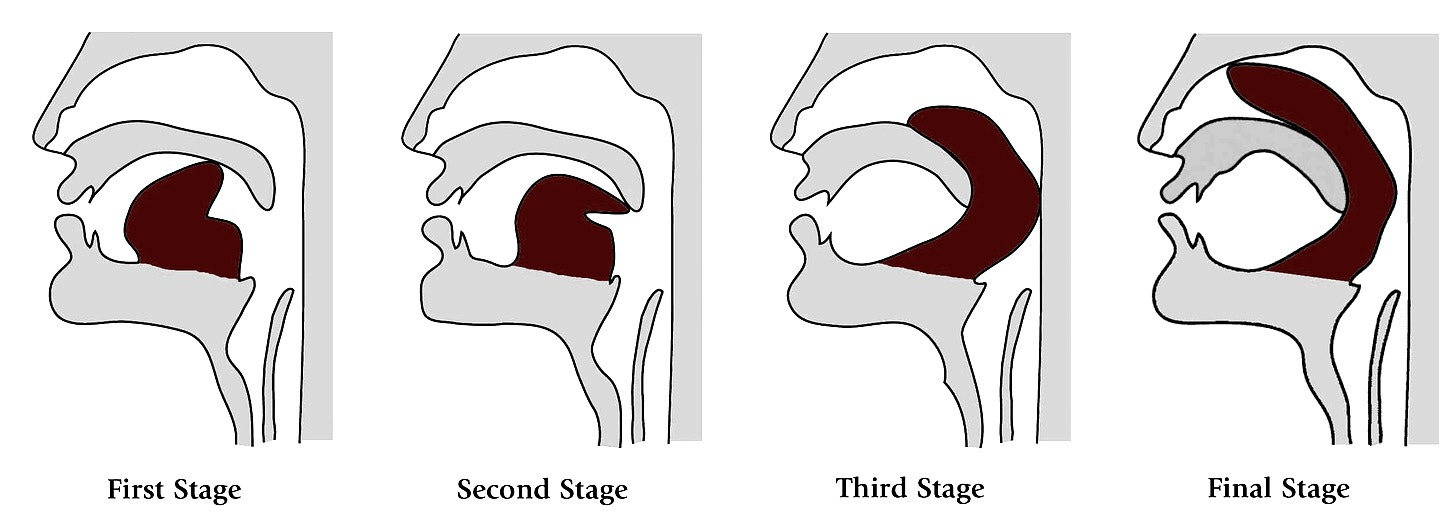
Integrating these unordinary tongues into the IPA system would require significant expansion and reconfiguration from within. As trivial and unbothersome as this observation may be to the actual field, it demonstrates the fragile boundaries of language as we define it.
Integrating new sounds
These observations excite me. To me they are actual examples of the linguistically possible, sitting right on the edge, where I could grasp them and use as a rung to plunge deeper into possibility. As if by reckoning with it, I could unfold the edges a little bit more.
With the help of Dr. Allard Jongman, a linguist specializing in phonetics from my alma mater, I adapted the IPA chart to accommodate these adaptations and assigned the distinct components a unique symbol. Here is a side by side with the original chart with my own, additions highlighted in yellow:
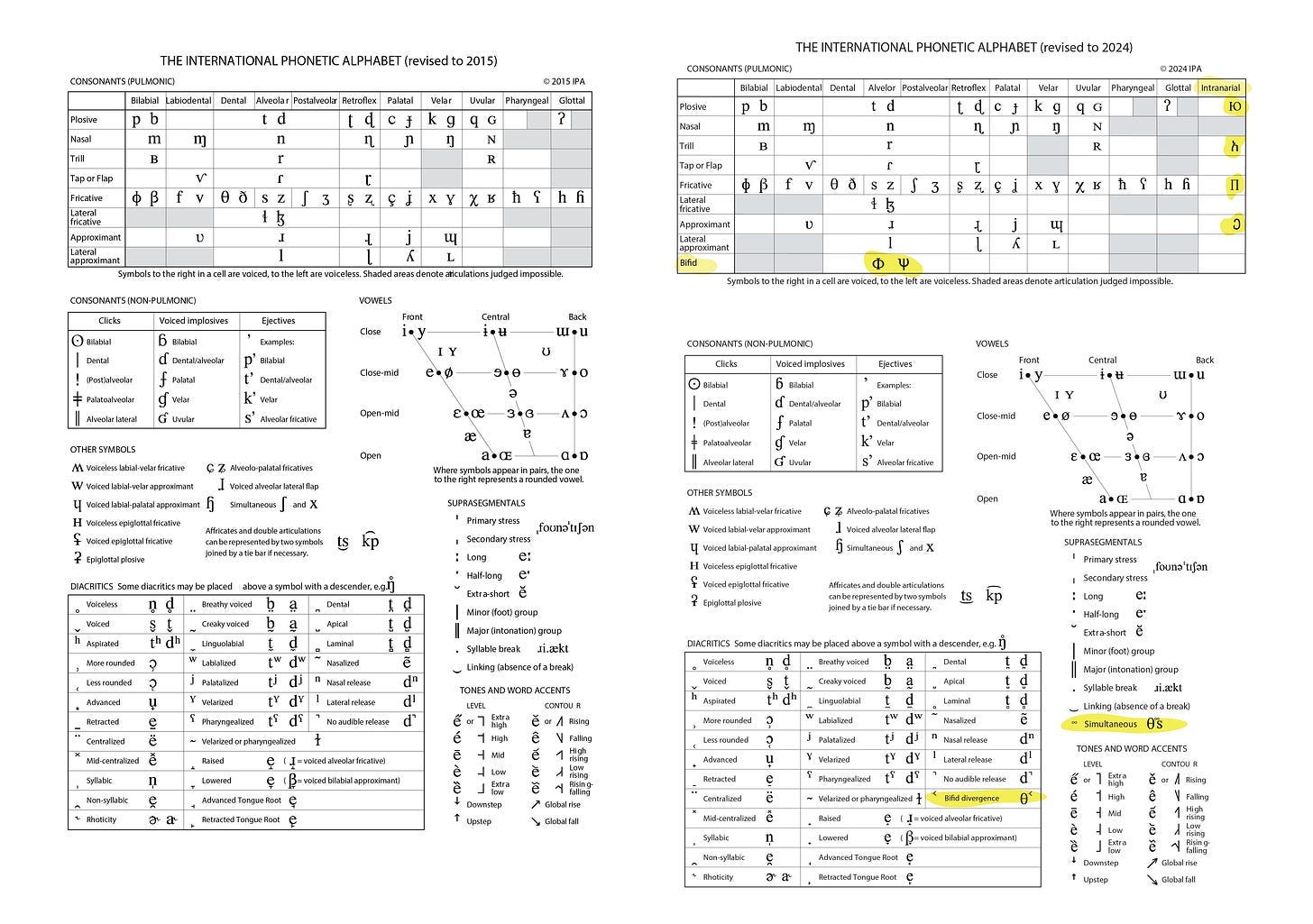
The rows on the consonants table describe manner of articulation. This is how air is constricted with the mouth and tongue which influences the sound. Having a split tongue would allow the speaker new manners of articulation because they have two tongues3. This I dubbed a bifid.
The columns describe place of articulation, or where in the mouth the tongue makes air constriction. People who can do Khecarī mudrā are capable of articulation in the nasal cavity, dubbed intranarial.
Finally there are subsections of the chart that describe nuanced qualities in speech production that describe things like intonation, stress or breathy voice.
Consonants
Φ and ѱ
Bifids. These symbols, φ (phi) and ѱ (psi) were selected because they are unclaimed in IPA and visually represent a two pronged affair. Their distinction is in the voicing: φ is voiceless (no vocal fold vibration), while ѱ is voiced (with vocal fold vibration).
These symbols account for any phones produced in this manner within the 3 places in the chart. It’s created by keeping the tongue tips together while relaxing the downstream musculature, creating a slit where air flows, yielding distinctive sound.
/Φ/
/ѱ/
Ю
Intranarial Plosive. Airflow is completely blocked, then suddenly released. Similar to /k/ but intranarial.

አ
Intranarial Trill. A trill is produced by rapid oscillation between articulatory positions, generally of the tongue but also lips. Akin to a rolling r, but would occur in the nasal cavity.
∏
Intranarial Fricative. A fricative describes a sound made by partial air obstruction that creates turbulence, like in /f/ and /s/. Here, obstruction occurs in the nasal cavity.
ე
Intranarial Approximant. Almost like a vowel, but still a consonant for complicated reasons I’m not getting into. Air constriction is slight, like an /l/, but occurs in the nasal cavity.



Diacritics
Diacritics capture subtle differences in pronunciation. Even with identical manner and place between phones, minor variations create distinct sounds.
᚜
Bifid Divergence. This symbol, an ogham, I chose to denote a sound produced with the two tongues spread apart. The gap yields a subtle yet distinctive quality.
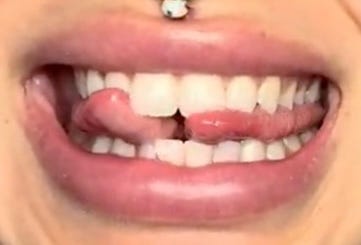
[θ᚜]
Suprasegmentals
These are phonetic features that extend beyond units of sound like stress and intonation.
∞
Simultaneous. Made possible with two tongues, this symbol was chosen to denote when two sounds occur simultaneously. One tongue tip could be placed between the teeth while the other rests behind, producing two sounds simultaneously.
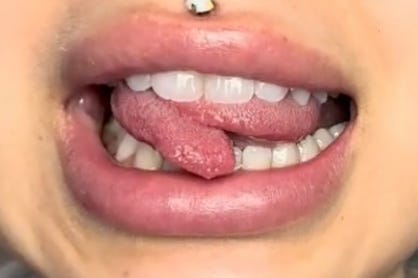
Transcribed as [θ∞s].
So there you have it— newly defined speech sounds. While they’re not officially recognized in any known language, they are legitimate phonetic possibilities, producible by living human beings.
Voice as a tangible frontier
Now consider how the field of linguistics would have to contort to accommodate a talking dog. Reckoning with non-human language means entering a speculative space so vast and abstract that even Chomsky’s prevailing theory of universal grammar may have to be relinquished as universal.4
Thee one dimension of language we can meaningfully investigate in other species is vocalization. Since it has everything to do with anatomy. Knowledge of animal anatomical systems grant us a measurable and finite “sound-making” search space. The mechanics for vocalization are so concrete that they can even be produced in a corpse— for example, the prosectors who made a dead lion roar.
The future of talking heads
I work for an animal genetic engineering lab. We build technology for scalable embryo editing and are interested in designing physical traits, improving vitality, and pulling the levers of intelligence in animal species. It’s a flavor of biotechnology that I sometimes call zootechnology. I spend a lot of time thinking about how genetic manipulation could change organisms in profound ways. Anatomically, socially, psychologically, linguistically.
For all its adaptability, language has remained a species-specific trait of humans. In this century we may influence its evolution as a device for functional communication. Our technologies could indirectly cause language to hybridize and mutate, become something stranger, something less human and more universal.
A poly-species linguistic future, homegrown or alien, invites us to restructure language as a device through which meaning is made and shared. Language is a medium of comprehension and an interface between nodes of observation. If we seek to understand the universe, we should seek to develop one of the primary modes used in understanding it.
Tricky said it best— How can we learn the universe, if we can’t even converse in universe?5
Thank you to phonetician Dr. Allard Jongman for the feedback on conceptualizing new phonetic sounds, and thank you to Bri Uvina for modeling and recording sound.

https://mproctor.net/docs/proctor10_IS2010_beatboxing.pdf
https://www.internationalphoneticassociation.org/icphs-proceedings/ICPhS2015/Papers/ICPHS0461.pdf
https://www.researchgate.net/publication/248226423_Universal_Grammar_and_Semiotic_Constraints